
In the previous article, [From Basics to Advanced – The Complete Producer-Consumer Model Guide](https://xx/From Basics to Advanced – The Complete Producer-Consumer Model Guide), we introduced the producer-consumer model and mentioned Kafka as a representative implementation in the big data ecosystem. In this article, we’ll dive deeper into Kafka, exploring what it is, how to use it, and its practical applications.
What Is Kafka?
Kafka was originally developed by LinkedIn and later donated to the Apache Foundation, becoming one of its top-level open-source projects. Kafka is a distributed, persistent, and high-throughput real-time messaging system designed around the producer-consumer model. It leverages Zookeeper for distributed coordination and is widely used for decoupling services, asynchronous communication, and real-time data transmission at scale.
Although Kafka is designed around the producer-consumer model, it differs significantly from the traditional implementation. Let’s first take a look at its design goals:
- Enable O(1) time complexity for message persistence, ensuring constant-time access even with TB-scale data.
- Provide high throughput and low latency, capable of handling over 100,000 messages per second on a single commodity server.
- Support distributed and concurrent consumption while maintaining message order within each partition.
- Allow for horizontal scalability.
And here are some of its key features that go beyond the traditional model:
- Supports multiple producers and consumers running concurrently.
- Allows consumers to replay messages and consume from specified offsets.
- Offers message durability with configurable retention policies.
- Provides fault tolerance through configurable replication.
Core Architecture
As mentioned, Kafka’s architecture is fundamentally based on the producer-consumer model. However, to meet its ambitious design goals, Kafka introduces three primary roles in its architecture: Producer, Broker, and Consumer.
- Producer is responsible for sending data (messages) to Kafka.
- Consumer subscribes to and reads messages.
- Broker is the Kafka server node that stores and routes messages.
Messages in Kafka are stored under topics, which logically isolate different streams of data. For performance and scalability, each topic is divided into multiple partitions, and each partition is further broken down into segments on disk to improve read/write efficiency.
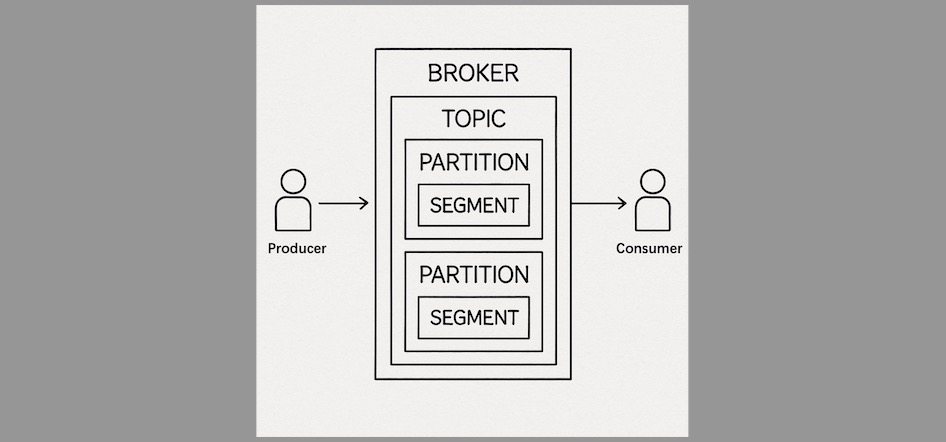
To ensure high availability and reliability, Kafka is typically deployed in clusters. Each topic’s partitions are distributed across different broker nodes, and Zookeeper coordinates metadata and cluster state, enabling Kafka’s distributed nature.
Getting Started
Now that we understand Kafka’s goals, features, and architecture, let’s get hands-on.
Before sending or consuming messages, you need to create a topic:
kafka-topics.sh --create --topic test-topic --bootstrap-server localhost1:9092,localhost2:9092,localhost3:9092 --partitions 3 --replication-factor 3This command creates a topic named test-topic with 3 partitions and 3 replicas for each partition.
Next, here is a simple Java program to produce and consume messages from this topic:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class SimpleKafka {
public static void main(String[] args) {
String topic = "test-topic";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost1:9092,localhost2:9092,localhost3:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("group.id", "demo-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
props.put("enable.auto.commit", "true");
try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {
for (int i = 0; i < 10; i++) {
String key = "key-" + i;
String value = "message-" + i;
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
RecordMetadata metadata = producer.send(record).get();
System.out.printf("Sent message to topic %s partition %d offset %d%n",
metadata.topic(), metadata.partition(), metadata.offset());
}
} catch (Exception e) {
e.printStackTrace();
}
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
consumer.subscribe(Collections.singletonList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Consumed message: key=%s, value=%s, partition=%d, offset=%d%n",
record.key(), record.value(), record.partition(), record.offset());
}
}
}
}
}Alternatively, you can use Kafka’s built-in CLI tools to produce and consume messages:
# Produce messages
kafka-console-producer.sh --topic test-topic --bootstrap-server localhost1:9092,localhost2:9092,localhost3:9092
# Consume messages
kafka-console-consumer.sh --topic test-topic --from-beginning --bootstrap-server localhost1:9092,localhost2:9092,localhost3:9092Use Cases
Kafka has become a cornerstone of the big data ecosystem due to its versatile capabilities. Here are some common application scenarios:
- Real-time Data Processing
Kafka serves as a data ingestion layer for real-time processing systems like Flink and Spark Streaming. It can also act as a temporary data store for streaming pipelines or even as part of a real-time data warehouse. - Event-Driven Architecture
Kafka topics can act as triggers for business logic. Consumers can subscribe to specific topics and perform actions upon receiving certain messages. - Centralized Log Collection
Kafka can collect logs from servers, containers, or applications, providing a reliable pipeline for centralized log analysis and visualization.
Conclusion
Kafka is far more than a traditional messaging queue. It is a robust, distributed implementation of the producer-consumer model tailored for the big data era. With support for message persistence, distributed replication, and flexible consumption models, Kafka has become a foundational technology in modern data systems.
In the next article, The Design Philosophy of Kafka, we’ll go under the hood to understand the engineering brilliance that powers Kafka’s high performance, reliability, and consistency in distributed environments.